Vehicle data campaigns are the fastest way to answer new, high-impact questions about vehicles in the field without permanently increasing baseline telemetry volume. At Rivian, campaigns must target large cohorts, route through different gateway paths for different vehicle variants, and produce results that are queryable by operational applications with predictable latency. The system also has to support multi-region high availability, high volume, high throughput, and comply with privacy and region-aware data governance regulations. This article explains what a data campaign service is, why scaling it can be challenging for automakers, and how Rivian solved those scalability challenges using MongoDB. We also share forward-looking development directions, such as using semantic search to shorten triage cycles and improve the reuse of past campaign outcomes.
Why data campaigns matter at fleet scale
Fleet-scale vehicle data systems must satisfy two requirements that frequently conflict: they must support continued growth in connected-vehicle data volume, and they must enable rapid, targeted investigation when unexpected behavior appears in the field. Industry analysis continues to project sustained growth in connected vehicle adoption over the next decade as automakers look to use vehicle data to improve the product and keep the cost of data collection and processing under control. At the same time, engineering teams want to shorten the development and testing cycles. They want to quickly understand the impact of a specific software build, validate behavior in a specific region, or isolate an anomaly to a specific vehicle configuration or time window. Those investigations require controlled, cohort-specific data collection rather than a blanket increase in baseline telemetry.
Recent industry research suggests that connected vehicle data rates could reach extremely large magnitudes over time, including figures on the order of tens of gigabytes per hour per vehicle. Even if only a small portion of this data needs to be queried operationally, pulling everything in by default drives up transmission and storage costs, pushes write and query loads to their limits, and makes it harder to keep the system stable over time. Additionally, regulators and policymakers are looking much more closely at the data privacy and security implications of connected vehicle data. In practice, the platform needs a deliberate way to ask for exactly the data it needs from a known vehicle cohort, control how and when those requests roll out, and enforce geo-aware data governance, while still meeting the latency and availability expectations of customer-facing services. A data campaign service provides such a capability.
What is a data campaign service?
A data campaign service (DCS) is essentially the control layer that turns a data collection request into coordinated activity across the fleet. The following steps are involved in creating a campaign:
Picking the vehicles we care about
Describe what, when, and how we want them to send
Set/Update any guardrails around policy and governance
The service then pushes those instructions, tracks which vehicles have responded, and makes the results available to downstream applications. The key point is that this is not just running a query on data we already have. A campaign asks vehicles to generate new data on demand, creating spikes in data traffic on top of existing data collection pipelines.
At Rivian, the campaign service sits on top of a real-time vehicle data foundation used by multiple applications. Data collection campaigns, therefore, have to coexist with, and not degrade, the core customer vehicle experiences that those applications support.
Reference architecture at Rivian
Rivian’s telemetry path is designed to support real-time ingestion and aggregation. Vehicles send data through a gateway tier into a time series database (TSDB), where substantial aggregation occurs, and curated outputs are written into MongoDB Atlas for downstream application consumption. Application teams access campaign data through REST APIs exposed by the campaign service. The service uses MongoDB to determine which vehicles qualify for a given campaign, persist campaign metadata, and maintain the operational state needed to run and monitor campaigns. When applications retrieve campaign data, the service reads from MongoDB using paginated calls and, where needed, aggregation pipelines to return the required results efficiently.
The campaign service itself is organized into data and control planes because campaign metadata and campaign outputs behave very differently at scale. The control plane stores campaign cohort definitions, rollout state, policy constraints, and the rules that say which Electronic Control Units (ECUs) and signals are allowed for that campaign. This information is relatively small but must be consistent everywhere, so it is kept in a MongoDB replica set that is replicated across regions. The data plane holds the operational results of those campaigns including aggregated latest states and cohort-specific metadata e.g. cars in US/East, which all campaigns are sent out to which car, did cars accept the campaigns, did a car face issues processing campaigns etc. This data grows with fleet size and with the number and intensity of campaigns, so it is horizontally scaled through geo-sharding and kept in the regions where it is generated and queried. Each MongoDB shard is also replicated to improve availability and support higher read throughput for campaign APIs and operational queries.
Figure 1 reflects the data and control flow, including the upstream aggregation path, MongoDB as the operational store, and the campaign service split into replicated control planes and sharded data planes.
Figure 1. A data architecture view of the data campaign service.
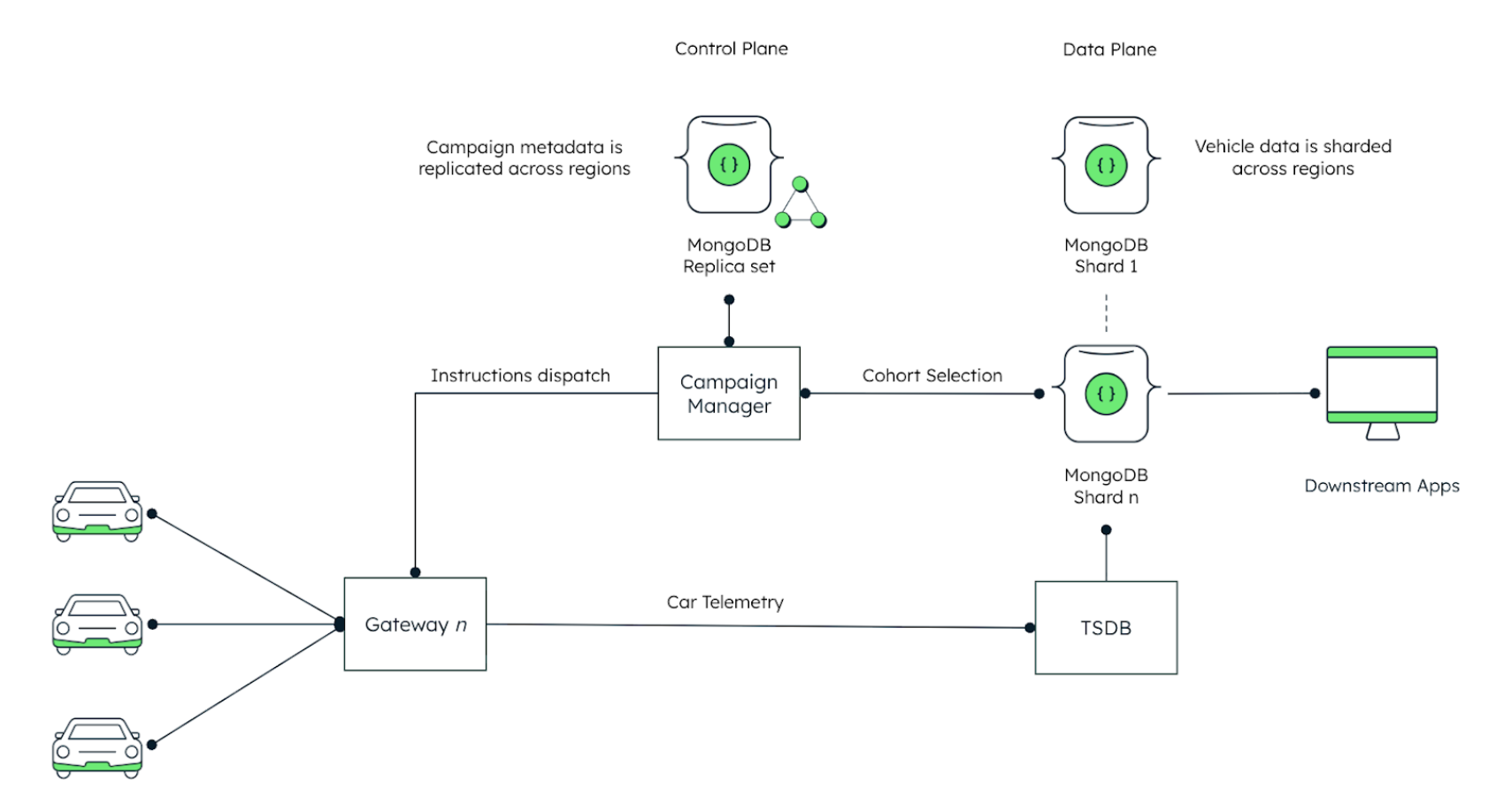
In Figure 1, the campaign manager sits in the middle and orchestrates the entire data campaign lifecycle. Campaign definitions and metadata are stored in a MongoDB replica set to ensure replication across regions and remain available even during failures. When a new campaign is created, the Campaign Manager queries the MongoDB cluster that holds vehicle and ECU metadata to select the target cohort based on the configured filters, such as vehicle attributes or data source. It then sends collection instructions to the appropriate gateway, which forwards those instructions to the vehicles and later accepts their telemetry uploads. Car telemetry flows into a time-series database for high-volume ingestion and aggregation, and campaign-relevant operational outputs are then persisted to the sharded MongoDB cluster via highly scalable stream-processing pipelines using efficient batch writes. Within each shard, replication is used to maintain availability and durability, including a replica in another region to protect against regional failure, while the control plane also replicates across regions with the expected cross-region write latency trade-offs. In this design, MongoDB is not the primary store for raw vehicle telemetry, but for the operational campaign state and some aggregated insights that applications need to query.
The replica set provides a durable, globally-consistent control plane for campaign metadata, while the TSDB and broader data platform handle raw telemetry, and the sharded MongoDB cluster serves the campaign-relevant operational data plane for aggregated state and campaign results.
Two implementation details matter for scalability reasons: First, cohort selection happens against MongoDB because it holds the operational vehicle inventory, ECU descriptions, and attributes used to define which vehicles are in scope for each campaign. Second, instruction dispatch must route through the correct gateway, as different vehicle types can send their data to different gateways. The campaign service, therefore, needs a reliable way to map vehicles to the right gateway and to control how fast it sends work to each gateway, so that no single path is overwhelmed.
Why MongoDB for campaign metadata and operational applications
Rivian chose MongoDB Atlas for the Data Campaign Service because its core features line up with how campaigns behave in production. Campaign workloads create short periods of concentrated writes into a small set of collections, followed by relatively low read traffic and occasional updates as each vehicle moves through the campaign lifecycle. The platform also has to work across regions, handle different vehicle and ECU signal sets, and integrate cleanly with the company’s streaming and analytics stack.
The Data Campaign Service is measured by its end-to-end predictability rather than by any single metric. The criteria-based filtering used to define the initial vehicle segment happens before the campaign service begins its work. Once a campaign is created, the resulting target list is written into MongoDB Atlas, where the campaign manager uses it for campaign execution, tracking, and downstream application access. As the data model is aligned with application access patterns, this operation remains stable even as the fleet grows.
The Campaign Manager maps each selected vehicle to the correct gateway and sends collection instructions at a controlled rate so that no gateway is overloaded. Operationally, Rivian tracks the rate at which instructions are sent, expressed as X vehicles per minute, and the time it takes to reach a target participation level (e.g., 90% acknowledgement for a cohort of size X).
MongoDB sharding feature gives Rivian a way to spread vehicle-centric campaign data and target segments across multiple servers (shards) so that storage and write capacity can grow in a controlled, horizontal way as the fleet and the number of campaigns increase. Because MongoDB shards are replica sets, each shard can be placed in the geography that makes sense for that slice of data, keeping campaign results close to the region where they are generated and queried, while also maintaining at least one replica in another region to protect against data loss in the event of a full regional failure.
MongoDB replica sets are used to ensure high availability of the control plane and campaign metadata. This gives the data campaign service a predictable failure model, which is important when campaigns might be running while maintenance or incident response is taking place elsewhere in the stack.
Multi-region deployment is handled through MongoDB Atlas multi-region clusters and global cluster zoning. Rivian can pin specific shards to specific regions and direct reads and writes to those shards based on vehicle or campaign attributes. This keeps sensitive vehicle-centric results in the region while letting the campaign manager see a single logical view of campaigns across the fleet.
Flexibility in the data model is essential because different vehicle lines and ECUs expose different signals, and policies do not always enable the same elements. MongoDB’s document model allows a collection of campaign result documents to be polymorphic. New signals can be added for new hardware or experiments by extending documents and, where needed, using schema version information, instead of enforcing a global schema change.
In-place updates are handled efficiently using batch updates and stream processing pipelines. Updating a single document in place to reflect the new state is simpler for the application than appending. Reads are relatively infrequent compared to writes – mostly driven by dashboards and follow-up analysis – so the data model is tuned for simple writes and range-based reads.
Updating campaign state directly within the relevant documents keeps the application logic simpler than relying on an append-only pattern for every change. Reads are relatively infrequent compared with writes and are mostly driven by dashboards and follow-up analysis, so the data model is tuned around efficient write paths and predictable range-based reads.
Integration with streaming systems is handled through MongoDB change streams and the Kafka connector. When campaign state changes or new target segments are written, those changes can be streamed into Kafka topics and on to downstream platforms such as analytics environments or feature stores without a separate ingestion path. This matches the requirement to move target segments out of MongoDB once they have served their operational purpose, while still treating Atlas as the primary store throughout the active life of a campaign.
Vector search as the next lever for faster triage
Once the campaign service is running reliably at scale, the main challenge becomes learning from campaigns quickly instead of repeating the same investigations. Campaign results sit next to a large amount of unstructured data, such as diagnostic text, engineering notes, and incident reports. Without good retrieval across both, it becomes easy for teams to redo work that has already been done.
MongoDB Vector Search gives Rivian a way to turn this history into something you can talk to. Campaign summaries can be embedded and stored in the same MongoDB cluster, so engineers can use natural language to ask for “campaigns that look like this one” or “what we saw last time we ran this policy in this region” and get back semantically similar work, even if codes or field names differ. The same capability can power an MCP-based agent or other assistant that sits on top of the campaign dataset and answers questions such as “which campaigns collected similar inverter signals on a given vehicle class, or what resolutions were applied in comparable situations.” Vector search becomes a natural feature extension of the existing data campaign service at Rivian.
Summary
Data campaigns give Rivian a controlled way to collect the specific data needed to validate changes and investigate issues, without permanently increasing baseline telemetry or compromising regional governance. MongoDB Atlas provides the right foundation for this pattern. Sharding allows campaign data and target segments to grow horizontally with the fleet and the number of campaigns. Replica sets and multi-region deployment keep the control plane and data plane available and aligned with locality expectations. The flexible document model accommodates different signals from different vehicles and ECUs without constant schema churn, while in-place updates simplify tracking per-vehicle states during high-volume write bursts. Change streams and the Kafka connector tie MongoDB Atlas into Rivian’s streaming environment, allowing campaign events to flow into downstream systems or data warehouses as needed. Vector Search opens a path to natural language access over campaign history and related knowledge, so future tools and agents can make better use of the data the platform is already collecting.
Next Steps
Learn more about MongoDB's Manufacturing & Mobility solutions.