Deep learning is a subset of machine learning and artificial intelligence (AI) that uses multi-layered neural networks to find patterns in large amounts of data, including unstructured data like images, audio, and text. Loosely modeled on the human brain, these networks learn to recognize faces, understand speech, and spot what doesn’t belong.
This article walks through how deep neural networks work, how their layers learn, the main model types, where deep learning shows up in everyday products—and the trade-offs that come with it.
Key takeaways
- Deep learning is a branch of machine learning that finds patterns in unstructured data—images, audio, and text—using multi-layered neural networks.
- A deep neural network mirrors the brain: layered neurons pass signals forward, learning by adjusting the weights between them.
- Training is the learning loop—a network predicts, then corrects its errors with backpropagation and gradient descent until accurate.
- Different architectures fit different problems: CNNs for images, RNNs for sequences, GANs for generation, autoencoders for anomaly detection, and transformers for language.
- In everyday use, deep learning powers facial recognition, recommendations, and self-driving cars—but it demands heavy data and compute and can act as a "black box."
Table of Contents:
- How is deep learning different from machine learning and AI?
- How is deep learning similar to the human brain?
- How is deep learning different from the human brain?
- What are the layers of a deep neural network?
- How does a deep learning model learn?
- What are the main types of deep learning models?
- How is deep learning used in the real world?
- What are the challenges in deep learning?
- Where is deep learning headed?
- FAQs
- Related resources
How is deep learning different from machine learning and AI?
AI is the broad field of getting machines to do things that normally need human intelligence; machine learning is the approach that figures out how to get them done; and deep learning is a type of machine learning that uses multi-layered neural networks to work out the solution itself, even when the data is messy and unstructured.
Another way to look at it is like a set of nested boxes: AI is the outer box, containing every kind of intelligent system; machine learning sits inside it; and deep learning is the core—the most specialized of the three that’s also a type of machine learning and AI.
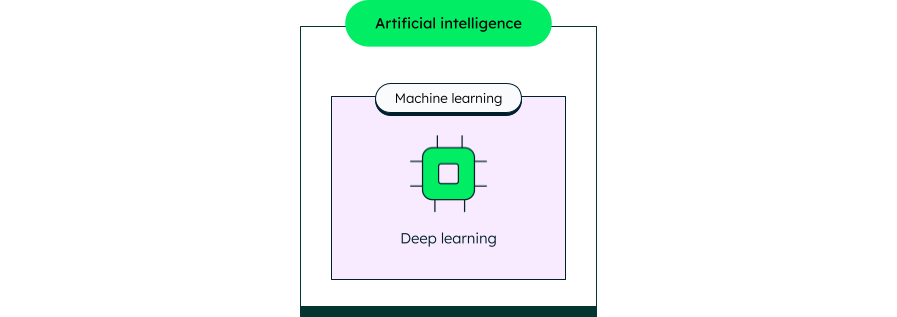
AI: The big umbrella
AI is the broadest field of the three—the umbrella that machine learning and deep learning sit under. It refers to machines that solve problems, learn, plan, understand language, and perceive the world. AI systems run on a mix of approaches, from simple rule-based logic ("if this, then that") all the way to complex machine learning algorithms.
Machine learning: Finding patterns in data
Machine learning models learn from data to perform certain tasks better over time, without being explicitly programmed for every step. They often train on labeled data—examples that come with the right answer attached—like photos tagged “cat” or “dog.”
Other types, like unsupervised learning, work with unlabeled data and find patterns on their own, without being handed the answers. Either way, the data almost always has to be cleaned up and organized first. Machine learning powers everyday tools like spam filters, credit scoring, and product recommendations.
Deep learning: A many-layered neural network
What makes deep learning “deep” is the number of layers it uses to learn—with each layer building on the one before it. In a deep neural network, an image passes through one layer after another, getting more refined at each step.
The first layers pick out simple features like edges and curves; deeper layers combine them into meaningful features that make up a whole object. Stack enough of these layers and the network learns what to look for on its own, with far less human intervention than older methods needed.
This is where deep learning breaks from traditional machine learning:
- Traditional machine learning: Human engineers handle feature engineering by hand—writing code that tells the model what to look for, like the edges and curves that form a face.
- Deep learning: Its hidden layers perform feature extraction automatically, working out which patterns matter without being told.
How is deep learning similar to the human brain?
Deep learning borrows its basic shape from the brain: both use large numbers of simple connected units that pass signals along and learn from experience. In the brain, those units are biological neurons joined by synapses. In an artificial neural network, each unit takes in numbers, weighs them, adds them up, and passes a single number on—also called a mathematical neuron, the network’s version of a brain cell.
The connections between these neurons act like synapses—each connection between neurons carries a value called weight—a number (one of the network’s parameters) that gets tuned as the network learns.
- Layered processing: The brain processes information in stages; specialized layers process information, pulling in simple sensory data to achieve full understanding. Deep learning’s layers work the same way—the network’s version of staged brain regions.
- Pattern recognition: The brain and deep learning are both good at spotting patterns and acting on them. A deep neural network learns the patterns and connections in data, such as which pixels form a shape or how words relate in a sentence—roughly the way a brain learns to remember faces, voices, and language through repeated exposure.
How is deep learning different from the human brain?
Comparing deep learning and the brain is a helpful metaphor, not a perfect match. The human brain is still far more capable, efficient, and adaptable than any artificial neural network.
- Consciousness and reasoning: The brain has awareness, abstract reasoning, and emotion. Neural networks can imitate narrow slices of thinking, like recognizing and predicting, but they don’t truly understand what they’re doing, or reason the way people do.
- Learning requirements: A child can learn what a giraffe is from one picture and recognize a cartoon giraffe later. Deep learning models usually need an enormous labeled dataset and heavy computing power to reach comparable performance—and only on the specific task they were trained for.
What are the layers of a deep neural network?
Deep neural networks employ multiple layers of connected nodes (neurons), passing data from one to the next. Every node connects to every node in the next layer, with data flowing left to right. Data enters at the input layer, moves through one or more hidden layers where the computation happens, and exits at the output layer as a result. Each node holds a value—a pixel, a feature, or a piece of text turned into numbers text embedding).
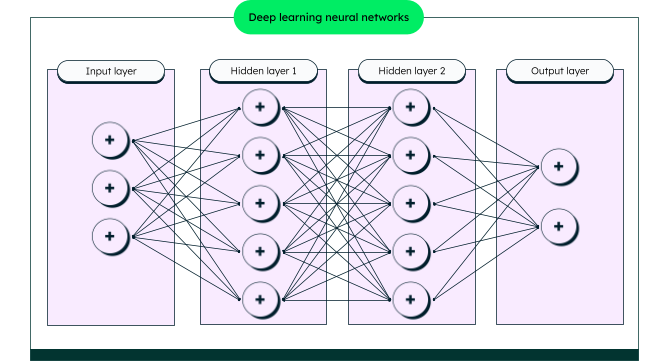
- Input layer: Takes in the data as numbers. For example, a photo becomes a grid of pixel values, one value per node.
- Hidden layers: The layers between input and output, where most of the work occurs. A network can have one or several, and each one passes its results on to the other layers. Two things that make these hidden layers work are:
- Weights and biases: A weight determines how much influence one neuron has on the next; a bias shifts the results up or down. The network adjusts these as it learns.
- Activation functions: These decide how much signal a node passes on. They add non-linearity—using mathematical functions like ReLU (rectified linear unit) and sigmoid—which allows the network to learn complex, curved relationships instead of just straight lines.
Output layer: This final layer gives the result. For an app that identifies plants from a photo, the result might be “87% chance it’s a sugar maple.”
How does a deep learning model learn?
Training a deep learning model means adjusting the weights and biases until the model’s predictions are reliably close to correct. The adjustment happens by repeating two steps: forward propagation and backpropagation. The steps are both guided by an optimization method (algorithm) called gradient descent.
- Forward propagation: The network runs a piece of training data through its layers and returns a prediction using its current weights, biases, and activation functions. Training a deep neural network usually starts with its weights set to random values, so at the beginning the guess is barely better than a coin flip.
- Backpropagation: After forward propagation, the model compares its guess to the right answer using a loss function (a score for how wrong it was), then works backward through the layers, adjusting weights and biases to minimize that error. Backpropagation just means propagating the error backward so each layer knows what to do to improve.
- Gradient descent: This is the optimization algorithm that does the adjusting. It changes each weight a little in whatever direction makes the error smaller, checks again, and repeats—until the error is as low as it can go.
- Iterative learning: The network repeats forward propagation and backpropagation with gradient descent many times. Each full pass through the training data is called an epoch, and with each epoch—each pass over the data points—the accuracy climbs and the error drops.
In practice, that means feeding the network a large labeled dataset and letting it correct itself round after round, until it’s learned the pattern well enough to classify new data it has never seen before with high accuracy. MongoDB Atlas is often used to store and serve the large, varied datasets these training workflows depend on, thanks to its flexible document model and ability to scale.
What are the main types of deep learning models?
Not all neural networks are built the same way. Different problems call for different designs—or architectures—and the five that are used most often are CNNs, GANs, RNNs, autoencoders, and transformers. Each is built to handle a particular kind of data, but training deep learning models of any type relies on the same process: forward propagation, backpropagation, and gradient descent.
The top five deep learning models compared
RNNs have a memory limit: Over a long sequence, the network loses track of how things started—the vanishing gradient problem. A variant called long short-term memory (LSTM) holds on longer, so the start of a sequence can still shape the end. RNNs are accurate but slow, which is why transformers have largely replaced them for language work. MongoDB time series collections are optimized for sequential data, a good fit for uses like sensor monitoring.
Why transformers work: Because self-attention takes in the whole sentence at once, they process data in parallel and sidestep the speed bottleneck that slows RNNs down. MongoDB Atlas supports semantic search through its Vector Search, so developers can store model embeddings and build search that understands meaning rather than just matching keywords.
How is deep learning used in the real world?
Deep learning is already woven into everyday tools: face unlock on a smartphone, streaming service recommendations, and tumor detection in medical scans. In each case, deep learning finds patterns in large amounts of data to recognize, predict, and generate.
Many of today’s apps use transfer learning to get the specialization they’re known for—starting from a model trained on large, general datasets and adjusting it for a narrower job like detecting fraud, reading a legal contract, or spotting defects on an assembly line.
Some of the most common uses:
Computer vision and facial recognition: Deep learning teaches computers to make sense of visual data, powering things like security systems and photo tagging.
MongoDB Vector Search can store image embeddings to power visual similarity search (finding images that look alike).
- Natural language processing (NLP): Deep learning allows machines to work with human language—translation, chatbots, and sentiment analysis (judging the tone of a piece of text).
With MongoDB Atlas, developers can build generative AI and semantic search right into their applications.
Autonomous vehicles: Self-driving cars use deep learning to detect obstacles, identify pedestrians, avoid collisions, and navigate, processing large amounts of streaming data from cameras and sensors.
MongoDB’s time series and geospatial features can store the sensor readings and GPS logs.
Speech recognition: Voice-to-text and voice-activated systems turn speech into a format that a computer can process and react to—the reason virtual assistants work as well as they do.
Once speech becomes text, MongoDB can store and search the resulting transcripts—call logs, captions, and voice notes.
Recommendation systems: Streaming and shopping platforms read the user’s past behavior and user preferences to suggest what they’re likely to want next.
MongoDB's flexible document model is a natural fit for the user profiles and product catalogs that recommendations run on, serving them in real time as behavior changes.
Medical imaging: Systems that use deep learning techniques can spot cancer cells in scans faster and more accurately than older machine learning techniques, which helps medical teams catch tumors sooner.
MongoDB can bring medical records and imaging data into one place for quicker diagnosis.
What are the challenges in deep learning?
Deep learning is powerful, but it comes with costs and limitations, too.
- Complexity: Tracking data as it moves through neurons and layers is difficult, which makes deep learning systems challenging to design and debug.
- Data requirements: Deep learning models need massive datasets to perform well—and acquiring that much quality data is expensive (and sometimes just not available).
- Computational resources: Neural networks run enormous numbers of small calculations, so training relies on GPUs (graphics processing units) instead of CPUs. All that horsepower is costly, whether bought outright or rented in the cloud.
- Training time: Depending on the size of the data and the network, training can take hours, days, or even months.
- Overfitting: A model can memorize the noise in its training data instead of the real pattern—acing its training examples but stumbling on new data. More training data and validation checks help prevent it.
- The “black box” problem: Unfortunately, deep learning can produce an answer without an easy explanation as to how it got there. This matters most in fields like healthcare, where transparency is vital.
- Bias and privacy: Because models learn straight from data, they can absorb and even amplify existing biases. Keeping them fair takes balanced datasets, active auditing, and ongoing monitoring after deployment.
Where is deep learning headed?
Deep learning has already improved pattern recognition, decision-making, and automation, and it continues to grow. Generative AI—the technology behind tools like ChatGPT and Midjourney—and AI agents (systems that can plan and accomplish multi-step tasks) build on the neural-network basics explained in this article. The open questions now are less about raw capability than about doing it responsibly: sourcing quality data, honestly accounting for the energy it takes, and weighing the ethical stakes.